正则表达式的懒惰模式多懒惰
作为程序员一定对正则表达式不陌生,而且都对它又爱又恨。爱在它对字符串的匹配或替换上的确很方便,恨在于要匹配的条件一多,成串的正则就只有写的人能看懂了。
匹配括号中的内容
这篇文章来讲一个我们常见的需求:匹配括号中的内容。这个需求在很多地方都会用得着,例如爬虫或者写模板引擎解析模板语言等。
下面是具体问题:1
2
3
4
{php $a = 1; php}
这是在我的模板引擎里面抽出来的例子,为了减少问题难度,标签结尾用了php}而不是单纯的},因为单纯的}会跟代码块的正常语句中括号冲突增加例子的复杂性。
当看到这个例子的时候,其实很多人都可以直接想到1
2
3
4
\{php.*php\}
这样就完了吧。但是作为模板引擎,就可能遇到下面的情况:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
{php $a = 1; php}
{php
for (;$a<10;$a++){
echo $a;
}
php}
{php $b = 1; php} {php echo $b; php}
这种情况下匹配的情况就如下: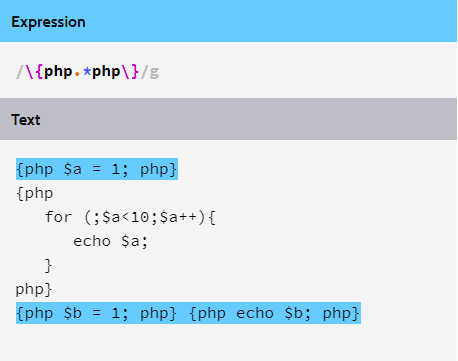
暂且不管中间的多行代码块,我们看到之前的正则只能匹配到首尾两行,而且最后一行的两个块都合在一起了,怎样将它们分开呢?
懒惰模式
答案是用正则的懒惰模式,正则的默认模式是贪婪模式,顾名思义就是有多少吃多少,直到吃到最后一个为止。而懒惰就是能不吃就不吃,能少吃就少吃。
先来看三个小例子:
1) 有一个字符串abccccc,如果使用ab.*来匹配的话,就会得到结果:
abccccc
因为*代表的是重复0次或无限次,就是说ab后面的只要不是换行符(\n)的字符,都会被匹配上。
2) 同样的例子,如果使用ab.*?,结果就会为ab,为什么不是abc?!
3) 那么如果?后面还有其他正则匹配呢?例如下面的例子:1
2
3
4
<p>mmm</p>
要分别匹配到p标签和里面的内容的话就要用到懒惰模式,<p>.*?p>,正如例子2)在匹配到第一个m的时候因为正则式还没结束,只能吃掉后面的字符直到吃到p>的时候就可以结束了。
回到第一节的例子:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
{php $a = 1; php}
{php
for (;$a<10;$a++){
echo $a;
}
php}
{php $b = 1; php} {php echo $b; php}
只要把表达式改成:1
2
3
4
\{php.*?php\}
这样就可以匹配到首尾两行的三个代码块了: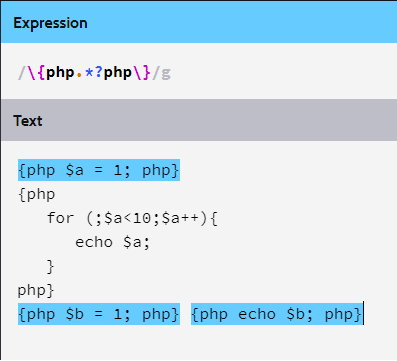
小总结
懒惰模式真是好东西。